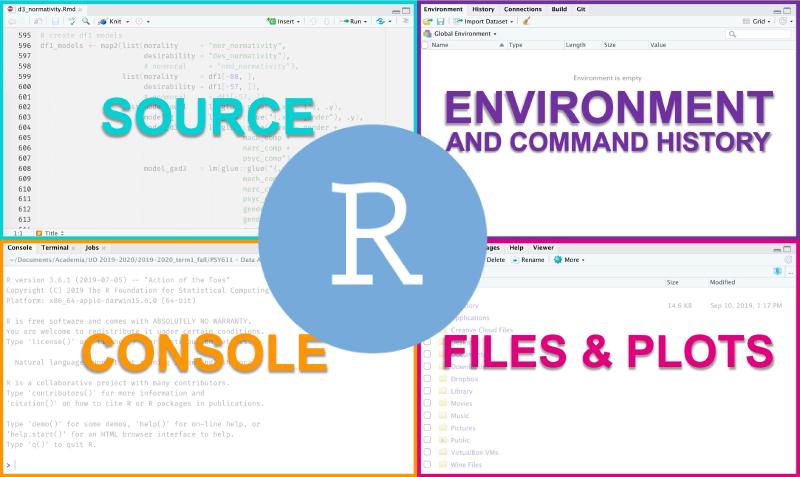
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
# 查看数据框的维数
dim(df)
# 查看数据框中的一列或一行
# 提取列有三种方式,使用列编号、列名或者$列名都可提取该列元素,而提取行元素只有前两种方法
# 与矩阵一样,也可以传入向量,对多个行或列进行提取
df[,1] # 第一列
df[,'y'] # 也是第一列
df$y # 还是第一列
df[1,] # 第一行
df['Sample_1',] # 第一行
# 数据框的排序。没有现成的方法,可以用order函数手工排序
df <- df[order(df$y,decreasing=TRUE),]
# 数据框的合并【重要!】
# by参数可以是单独的行名,或者多个行名组成的向量。在内连接时,程序会保留不同数据框中的by参数中所有列名对应的值完全相同的行,并合并。
# all参数设置为TRUE即完全外连接,即保留x和y中所有的条目,并合并by列值完全一样的行。
merge(
x, y, # 指定要合并的两个数据框
by = intersect(names(x), names(y)), # 选择保留哪几列,默认是列名取交集
by.x = by, # 分开指定列名,适用于x和y中列名不同,但含义一致的情况
by.y = by, # 同上
all = FALSE, # 是否做完全外连接(取x和y的所有行),默认是FALSE,即内连接
all.x = all, # 保留x中所有行(左连接),即使在y中找不到匹配也会保留
all.y = all, # 保留y中所有行(右连接)
sort = TRUE, # 对合并结果按by变量排序
suffixes = c(".x",".y"), # 若合并后两个数据框有相同的列名(非by列),则会加上相应的后缀
no.dups = TRUE, # 避免出现重复的列名
incomparables = NULL,
...
)
# 修改行名和列名。可以将数值或向量赋值给行名或列名。【不会循环补齐!】
colnames(df) = c('Y',paste('X', 1:9, sep='_'))
rownames(df) = paste('Sample',1:dim(df)[1],sep='_')
# 添加、删除、修改行或列。总体上与矩阵类似
df[3,5] = 1 # 修改某一元素
df$new = 1:dim(df)[1] # 修改一列,若该列名不存在,就添加一列
df <- df[,c(-1,-2)] # 删除第一列和第二列
# 转为矩阵
df <- as.matrix(df)
### 长宽表互相转换
library(reshape2)
# 使用melt将宽表转化为长表
long = melt(
df,
id.vars='y', # 保持哪些列不变,其余的列都会分裂成两列variable和value
)
# 使用dcast将长表转为宽表
wide = dcast(
long,
y ~ variable,
)
|